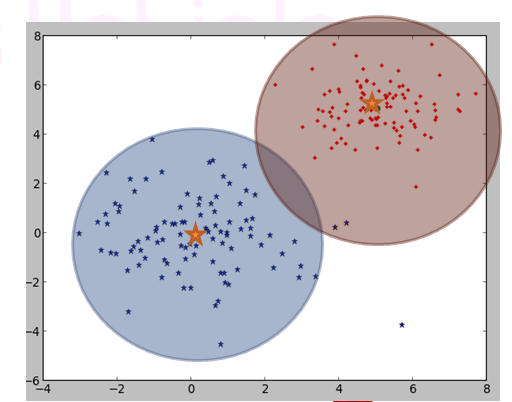
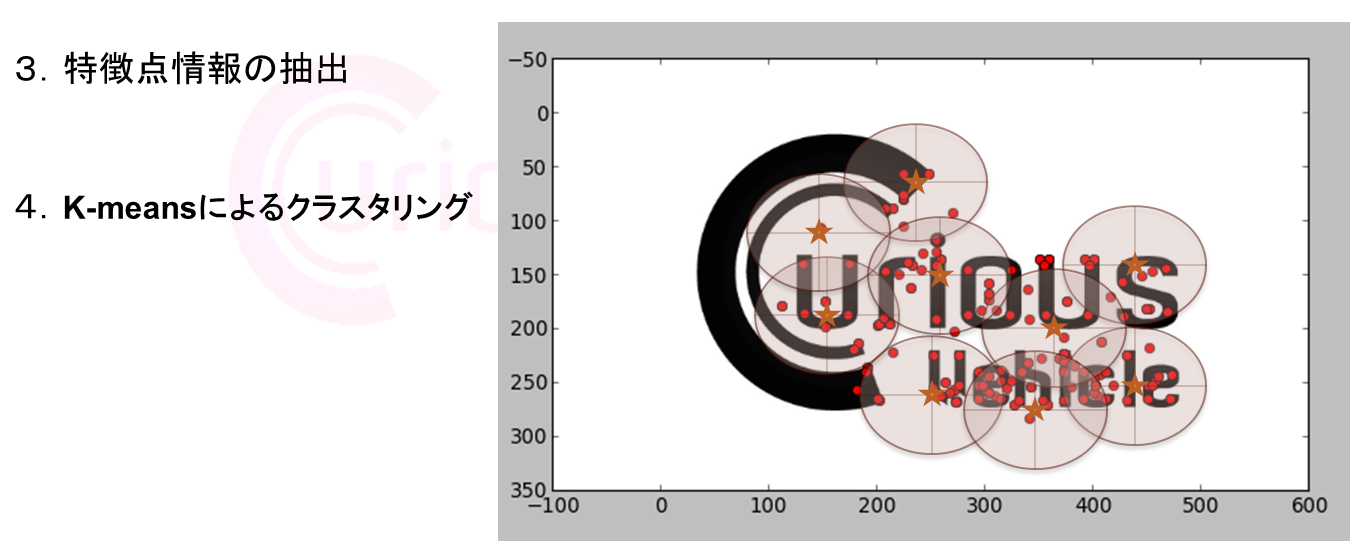
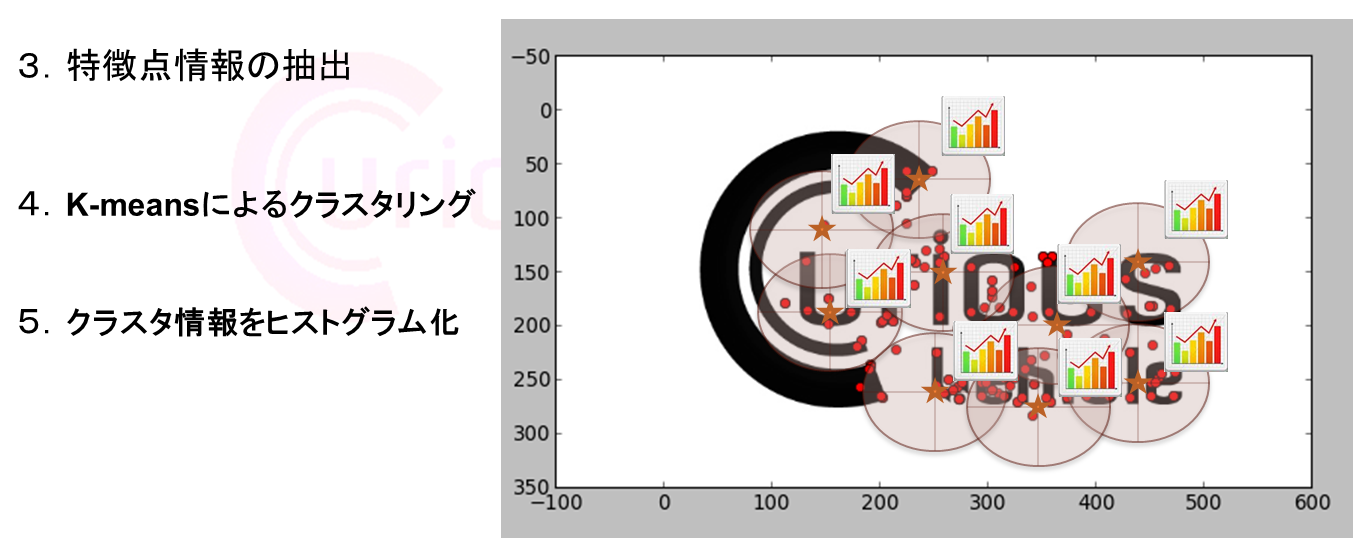
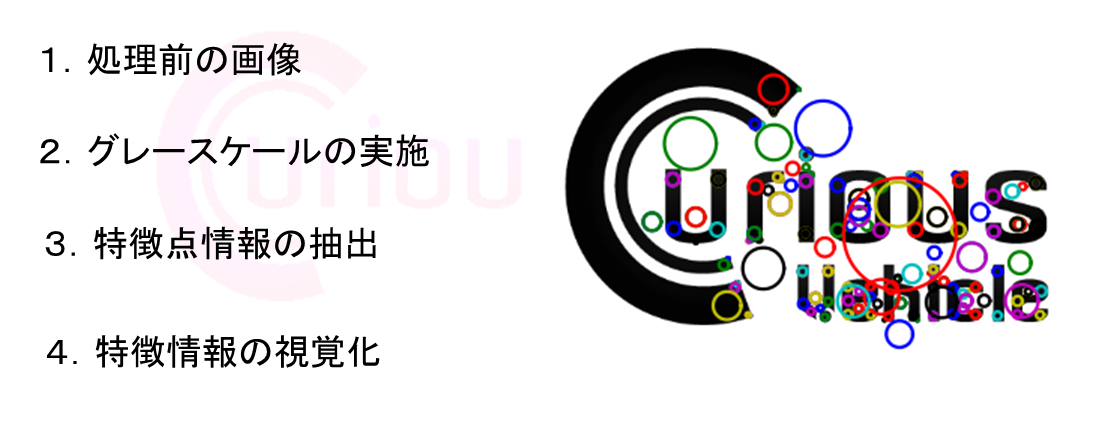
【Curious Vehicle 技術ネタ】
『Raspberry Pi を使用してスマホ操作可能なロボットを作成する』
みなさまご無沙汰しております。makino です。
- 今回は少しRaspberry Piでお仕事させていただく機会があり、こんな小さいなら動くLinuxマシンを作ろうと『Raspberry Pi を用いたロボット作成』についてこちらで発表させていただきます!

– 今回は初回なので簡単に目的を含め設計周りの説明をしたいと思います
[その1] 目的を考える
- ただ動くRaspberry Pi を作っても面白くないので、動くための目的を考えます。
- 今回は個人的な趣味性を強め 周りの人を『イラッ』とさせることを目的としたジョークロボットを作ろうと思います。
[その2] デザイン
- クレパスで挫折した私にデザインというのは一番ハードルが高かったですが、木材で囲っとけばなんとなるんじゃないかとデザインはほぼ考えずホームセンターに売っている木材で積み木のように組み立てることとします
[その3] 機能を考える
- 動きは『イラッ』っとする動きをしてくれないといけないですが、逃げ足も速くなくてはすぐに壊されるのである程度のスピードで狭いところに逃げ込むため小回りが利くくように左右別駆動の動力とします
- 『イラッ』っとさせたのを遠くから細く微笑んで見ていたいのでロボットにストリーミング用のWebカメラも必要です
- 動きだけでなく『イラッ』っとさせるしゃべりもしたいので、スピーカをつけてしゃべれるようにします
- 音が出せないところだと困るのでLEDをチカチカさせて『イラッ』とさせる機能も必要です
- ついでにディスプレイなどを消して逃亡するため赤外線機器を操作する赤外線LEDも追加します
- コントロールはNode.js経由でスマートフォンから操作できるようにします

- こんな感じのものが出来上がりました
- キーボードしか叩かないひよっ子にはこれが限界でした

- 中身はこんな感じになっています
続きについて
- 続きとしてはハードウェア編とソフトウェア編の2つを予定しています
- 無理やりですがSolrを用いた会話機能も考えているので期待してください