【Curious Vehicle 第14回 勉強会ネタ】
『Solrを利用した画像検索について』
みなさまご無沙汰しております。makino です。
* 今回は先日の第11回 Solr勉強会でお話しさせていただいた『Solrを用いた画像検索システム』についてこちらで発表させていただきます!
* テキストデータの検索ツールであるSolrで画像検索も行えたら今までとは違うインターフェースやサービスを作れるのでは!?
* Solr勉強会で話をさせていただいた時よりも改善を加えていますのでお付き合いいただければと思います!
【解説】Solrで画像を検索するための3ステップ

・画像情報はそのままでは検索が行えないので、Solrが得意なテキスト形式に画像データを加工していきます。
・そのファーストステップとして、①の『画像の特徴情報の抽出』を行います。
特徴点抽出アルゴリズム:SIFT特徴点解析
- まず特徴点抽出アルゴリズムとしてSIFTの概要をご紹介します
- SIFTアルゴリズムは画像内の特徴点の検出を行い、座標やスケールなどの情報を応答として抽出します
- SIFTでは各特徴点毎に以下の情報が取得できます
- ⇒ x座標
- ⇒ y座標
- ⇒ スケール
- ⇒ 回転角度
- ⇒ 対応する128の記述子
SIFT特徴点解析による特徴点抽出の流れ
- どのように動くか流れを見てみます!
- Solr勉強会の際は、著作権的にNGな画像を多量に使ってしまいましたが、今回は弊社のロゴで許してください
- ▼ 解析用の画像を準備します

- ▼ 今回は画像の特徴量情報を検索軸として利用するため、色情報をカットします

- ▼ SIFT特徴量アルゴリズムを実施し、特徴が検出された地点にプロットしています

- ▼ 特徴のベクトルをサークルの大きさで表示しています
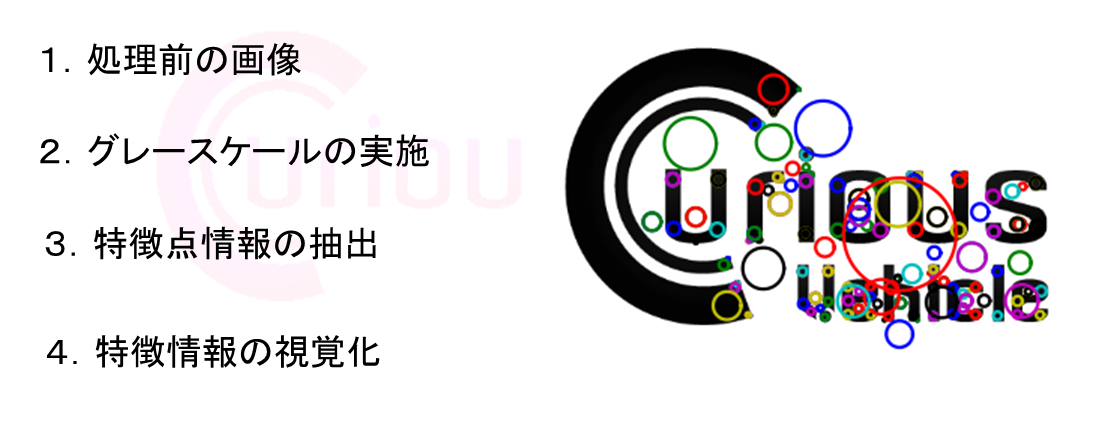
- ▼ 実際は各特徴点ごとに以下のような情報が数値化されて取得できます

* これらの解析処理を検索画像すべてに実施します
* この状態ではまだSolrのword情報(Term)としては少し情報が荒いため、②の『特徴情報のクラスタリングによるWord化』へ進みたいと思います
* 勉強会の際にお見せしたデモサイトも近いうちに公開したいと思います。よろしくお願いします!
Tips:Solr勉強会で質問いただいた点について
質問1:特徴量とクラスタリングの数のチューニングについて
- 今回はクラスタリング数をを100固定としてしまいましたが、今回の検索精度を上げるための1番のチューニングポイントだったのでまず検証を進めました
- 結果からとなりますが、特徴量の数に比例させk-meansによるクラスタ数を変化させましたが、検索精度の向上という部分とは紐づきませんでした
- ただこちらを調べているうちに特徴点の数が画像によりだいぶ検出数が異なっていることを確認しこちらを改善することで検索精度の大きな向上が見られました
- k-meansは計算量を減らすためのアプローチとして利用していますが、検索精度という意味でのアプローチではないため、DeepLearningや教師有り的なアルゴリズムへ次はチャレンジしようと思います
質問2:tf-idfにより画像の特徴がロストしてしまわないか
- 画像の特徴から作り出したTerm情報の頻度分布を見てみましたが、小さい特徴の塊が6~7割の割合を占め大きな特徴情報がうまくロングテールとなり検索精度の向上に繋がっているように見られました
※ 質問いただいた方とは、先日のトレジャーデータさんの懇親会でまたお会いしました。まさかトレジャーの方だったとは
There is definately a great deal to know about this topic. I love all
of the points you’ve made.