【Curious Vehicle 第14回 勉強会ネタ】
『Solrを利用した画像検索について』 Part2
また2週間ほど空いてしまいました。お疲れ様です.makino です。
* 今回は先日の第11回 Solr勉強会でお話しさせていただいた『Solrを用いた画像検索システム』について継続して共有をさせていただきます。
* 今回は特徴情報をSolrのIndexデータとしてまとめる部分についてご説明いたします!
【解説】Solrで画像を検索するための3ステップ Part2

・Part1で行った画像データの特徴情報化だけでは情報量が多くまた計算量も増えてしまうため、②の『特徴情報のクラスタリングによるWORD化』を行います。
クラスタリングアルゴリズム:K平均法クラスタリング(K-means)
- クラスタリングアルゴリズムとしてK平均法クラスタリングを簡単にご紹介します
- K-means は 入力データを k個のクラスタに分類する単純な分類機アルゴリズムです
- ランダムに振り分けたクラスタから各クラスタの重心を測定し、重心に近い座標で 再度重心計算とクラスタリングを繰り返すクラスタリング手法です
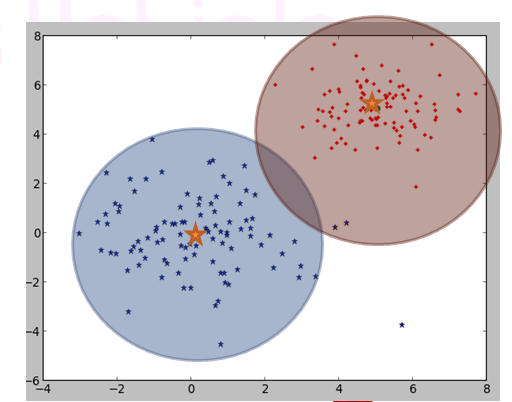
- 上記の図はクラスタリング数を2として 重心計算を20回繰り返した結果を示しています
K平均法クラスタリングによるクラスタリング処理の流れ
- 前回の復習も含め どのように動くか流れを見てみます!
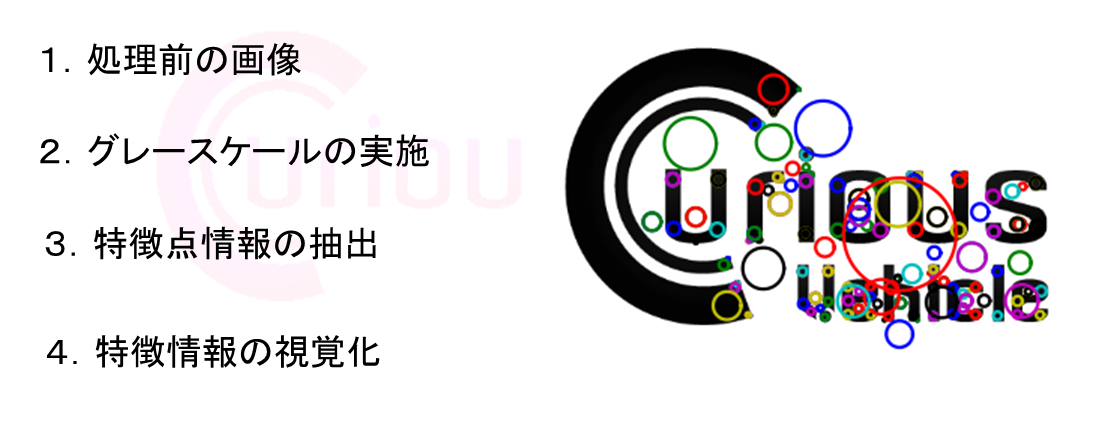
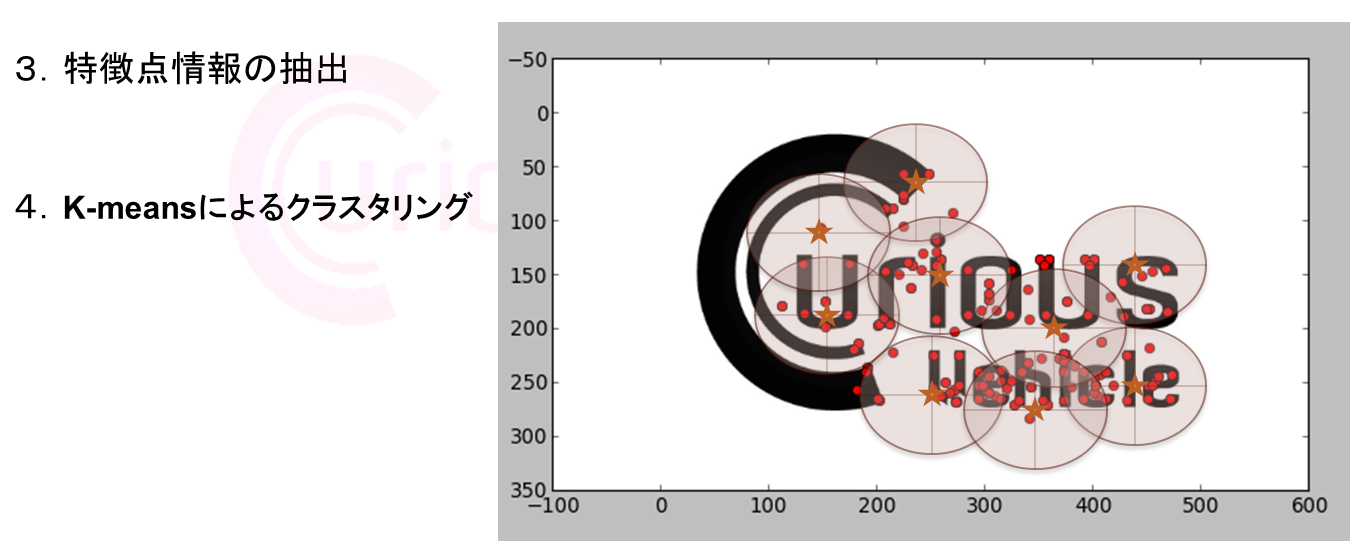
- ▼ 解析用の画像を準備します

- ▼ 今回は画像の特徴量情報を検索軸として利用するため、色情報をカットします

- ▼ SIFT特徴量アルゴリズムを実施し、特徴が検出された地点にプロットしています

- ▼ K平均法クラスタリングを利用し画像の特徴情報のクラスタリングを行います
- ▼ クラスタリング結果をヒストグラム化し、SolrのWORD情報として切り出します
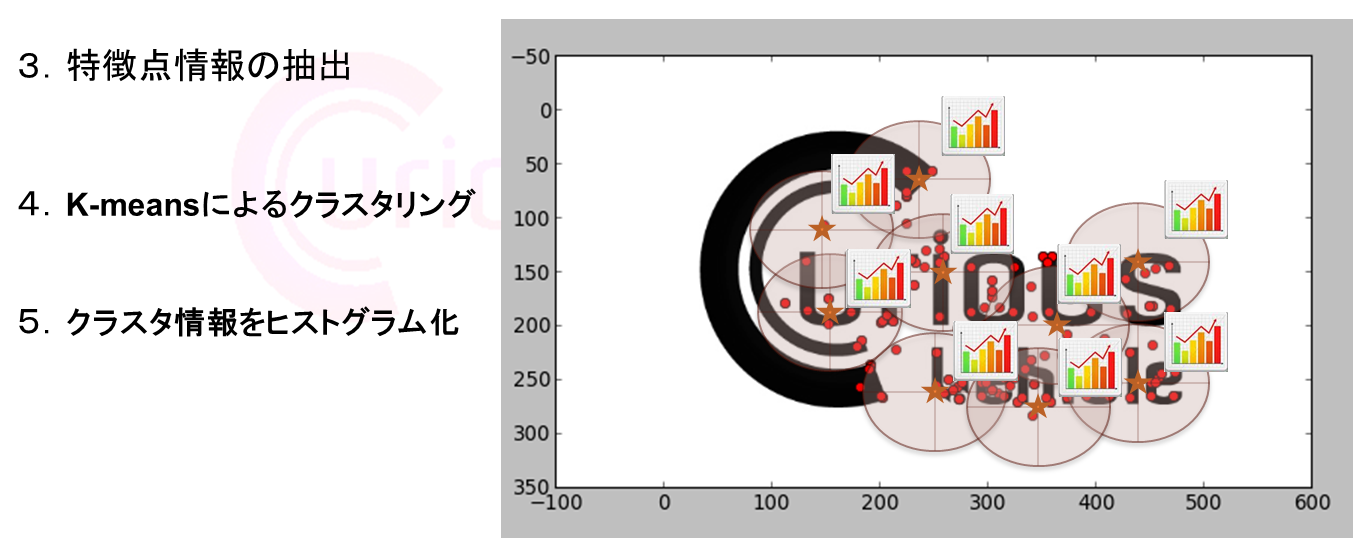
* これらのクラスタリング処理も検索画像すべてに実施します
* 勉強会の際はクラスタリング数を全画像100固定でクラスタリングを行っています
* この状態でやっとSolrに投入できる状態のデータが出来上がりましたので、③の『Solrによる画像情報の検索』へ進みたいと思います
Tips:Solr勉強会以降の進展について
その1:特徴量とクラスタリングの数のチューニングについて
- 前回、特徴量の数に比例させk-meansによるクラスタ数を変化させるようなチューニングでは検索精度の向上という部分とは紐づかなかったと書かせていただきました
- こちらの改善として精度向上が見られた点を共有したいと思います
- Part1でのTipsにも書きましたが、検索精度が低い画像は総じて特徴情報の量が少ない傾向がありました。
- 情報量が少ない画像は画像加工処理を追加し画像を回転させて再度特徴情報を取得することである程度安定した特徴量の抽出が行え、検索精度の高い向上が見られました
- Sift特徴量のアルゴリズムでは、特徴が発生した座標やアングル情報を持っていますが今回の画像検索では汎用性という意味でこちらの情報を利用せず特徴情報のみで類似検出を行っているためこのような結果につながっていると思います
- 用途が絞られるような画像検索であればもっとピンキーなチューニングにより精度向上が狙えると思うのですが、汎用性を踏まえ検証したところでは上記のようなチューニングで高い効果の確認ができました
- ※ 作業量の多そうな検証を省いたわけでなありません!たぶん!